# 使用事务执行 127.0.0.1:6379>MULTI OK 127.0.0.1:6379> set k100 v100 QUEUED 127.0.0.1:6379> set k200 v200 QUEUED 127.0.0.1:6379> get k200 QUEUED 127.0.0.1:6379>EXEC 1) OK 2) OK 3) "v200"
# 事务取消 127.0.0.1:6379>MULTI OK 127.0.0.1:6379> set k1 v1 QUEUED 127.0.0.1:6379> set k2 v2 QUEUED 127.0.0.1:6379> get k1 QUEUED 127.0.0.1:6379>DISCARD OK 127.0.0.1:6379> keys * (empty list or set)
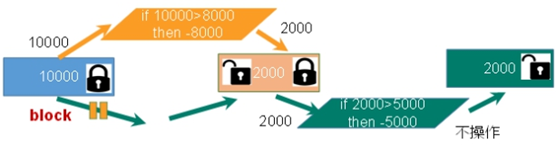
# 监控一个key 127.0.0.1:6379>WATCH k1 OK 127.0.0.1:6379>MULTI OK 127.0.0.1:6379> set k1 v1000000 QUEUED
# 另一个窗口修改k1 127.0.0.1:6379> set k1 00000 OK
# 回到第一个窗口提交事务 127.0.0.1:6379>EXEC (nil) 127.0.0.1:6379> get k1 "00000"
# CPU #将所有redis主进程在内核态所占用的CPU时求和累计起来 used_cpu_sys:203.44 #将所有redis主进程在用户态所占用的CPU时求和累计起来 used_cpu_user:114.57 #将后台进程在内核态所占用的CPU时求和累计起来 used_cpu_sys_children:0.00 #将后台进程在用户态所占用的CPU时求和累计起来 used_cpu_user_children:0.00
集群信息
1 2 3
# Cluster #实例是否启用集群模式 cluster_enabled:0
库相关统计信息
1 2 3 4 5 6 7 8 9 10
# Keyspace #db0的key的数量,以及带有生存期的key的数,平均存活时间 db0:keys=17,expires=0,avg_ttl=0 #单独查看某一个信息(例:查看CPU信息) 127.0.0.1:6379> info cpu # CPU used_cpu_sys:203.45 used_cpu_user:114.58 used_cpu_sys_children:0.00 used_cpu_user_children:0.00
#在0库中创建一个key 127.0.0.1:6379> set name zls OK #查看0库中的所有key 127.0.0.1:6379> KEYS * 1) "name" #进1库中 127.0.0.1:6379> SELECT 1 OK #查看所有key 127.0.0.1:6379[1]> KEYS * (empty list or set) //由此可见,每个库之间都是隔离的
flushdb、flushall
1 2 3 4 5 6 7 8 9 10 11
#删库跑路专用命令(删除所有库) 127.0.0.1:6379> FLUSHALL OK #验证一下是否真的删库了 127.0.0.1:6379> DBSIZE (integer) 0 127.0.0.1:6379> KEYS * (empty list or set) #删除单个库中数据 127.0.0.1:6379> FLUSHDB OK
monitor
开启两个窗口进行命令实时监控
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
# 在第一个窗口开启监控 127.0.0.1:6379> MONITOR OK # 在第二个窗口输入命令 127.0.0.1:6379> SELECT 2 OK 127.0.0.1:6379[2]> set name bgx OK 127.0.0.1:6379[2]> info # 在第一个窗口会实时显示执行的命令 127.0.0.1:6379> MONITOR OK 1540392396.690268 [0 127.0.0.1:35689] "SELECT""2" 1540392409.883011 [2 127.0.0.1:35689] "set""name""bgx" 1540392543.892889 [2 127.0.0.1:35689] "info"
shutdown
1 2 3
# 关闭Redis服务 127.0.0.1:6379> SHUTDOWN not connected>


 wechat
wechat alipay
alipay


{kind=link}