
7.Redis的主从复制
[toc]
Redis集群概述
由于单机Redis存储能力受单机限制,以及无法实现读写操作的负载均衡和读写分离,无法保证高可用。本篇就来介绍 Redis 集群搭建方案及实现原理,实现Redis对数据的冗余备份,从而保证数据和服务的高可用。主从复制是哨兵和集群的基石,因此我们循序渐进,由浅入深一层层的将Redis高可用方案抽丝剥茧展示在大家面前。
Redis主从复制介绍
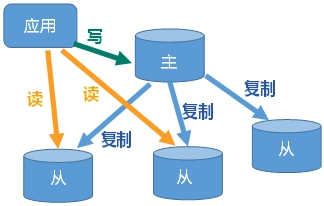
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器,主从是哨兵和集群模式能够实施的基础。前者称为主节点(master),后者称为从节点(slave),数据的复制是单向的,只能由主节点到从节点。默认情况下,每台Redis服务器都是主节点;且一个主节点可以有零个或多个从节点(0+个从节点),但一个从节点只能有一个主节点。一般主节点负责接收写请求,从节点负责接收读请求,从而实现读写分离。主从一般部署在不同机器上,复制时存在网络延时问题,使用参数repl-disable-tcp-nodelay选择是否关闭TCP_NODELAY,默认为关闭:
- 关闭:无论数据大小都会及时同步到从节点,占带宽,适用于主从网络好的场景。
- 开启:主节点每隔指定时间合并数据为TCP包节省带宽,默认为40毫秒同步一次,适用于网络环境复杂或带宽紧张,如跨机房。
主从复制作用
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务,分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
- 读写分离:主库写、从库读,读写分离不仅可以提高服务器的负载能力,同时可根据需求的变化,改变从库的数量。
- 高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础。
主从复制特点
- 使用异步复制。
- 一个主服务器可以有多个从服务器。
- 从服务器也可以有自己的从服务器。
- 复制功能不会阻塞主服务器。
- 可以通过复制功能来让主服务器免于执行持久化操作,由从服务器去执行持久化操作即可。
详细功能
- Redis 使用异步复制。从 Redis2.8开始,从服务器会以每秒一次的频率向主服务器报告复制流(replicationstream)的处理进度。
- 一个主服务器可以有多个从服务器。
- 不仅主服务器可以有从服务器,从服务器也可以有自己的从服务器,多个从服务器之间可以构成一个图状结构。
- 复制功能不会阻塞主服务器:即使有一个或多个从服务器正在进行初次同步, 主服务器也可以继续处理命令请求。
- 复制功能也不会阻塞从服务器:只要在 redis.conf 文件中进行了相应的设置, 即使从服务器正在进行初次同步, 服务器也可以使用旧版本的数据集来处理命令查询。
- 在从服务器删除旧版本数据集并载入新版本数据集的那段时间内,连接请求会被阻塞。
- 还可以配置从服务器,让它在与主服务器之间的连接断开时,向客户端发送一个错误。
- 复制功能可以单纯地用于数据冗余(data redundancy),也可以通过让多个从服务器处理只读命令请求来提升扩展性(scalability): 比如说,繁重的SORT命令可以交给附属节点去运行。
关闭主服务器持久化时,复制功能的数据安全
1.当配置Redis复制功能时,强烈建议打开主服务器的持久化功能。 否则的话,由于延迟等问题,部署
的服务应该要避免自动拉起。
2.为了帮助理解主服务器关闭持久化时自动拉起的危险性,参考一下以下会导致主从服务器数据全部丢
失的例子:
1)假设节点A为主服务器,并且关闭了持久化。并且节点B和节点C从节点A复制数据
2)节点A崩溃,然后由自动拉起服务重启了节点A. 由于节点A的持久化被关闭了,所以重启之后没有任
何数据
3)节点B和节点C将从节点A复制数据,但是A的数据是空的,于是就把自身保存的数据副本删除。
结论:
1)在关闭主服务器上的持久化,并同时开启自动拉起进程的情况下,即便使用Sentinel来实现Redis的
高可用性,也是非常危险的。因为主服务器可能拉起得非常快,以至于Sentinel在配置的心跳时间间隔
内没有检测到主服务器已被重启,然后还是会执行上面的数据丢失的流程。
2)无论何时,数据安全都是极其重要的,所以应该禁止主服务器关闭持久化的同时自动拉起。
主从复制的原理
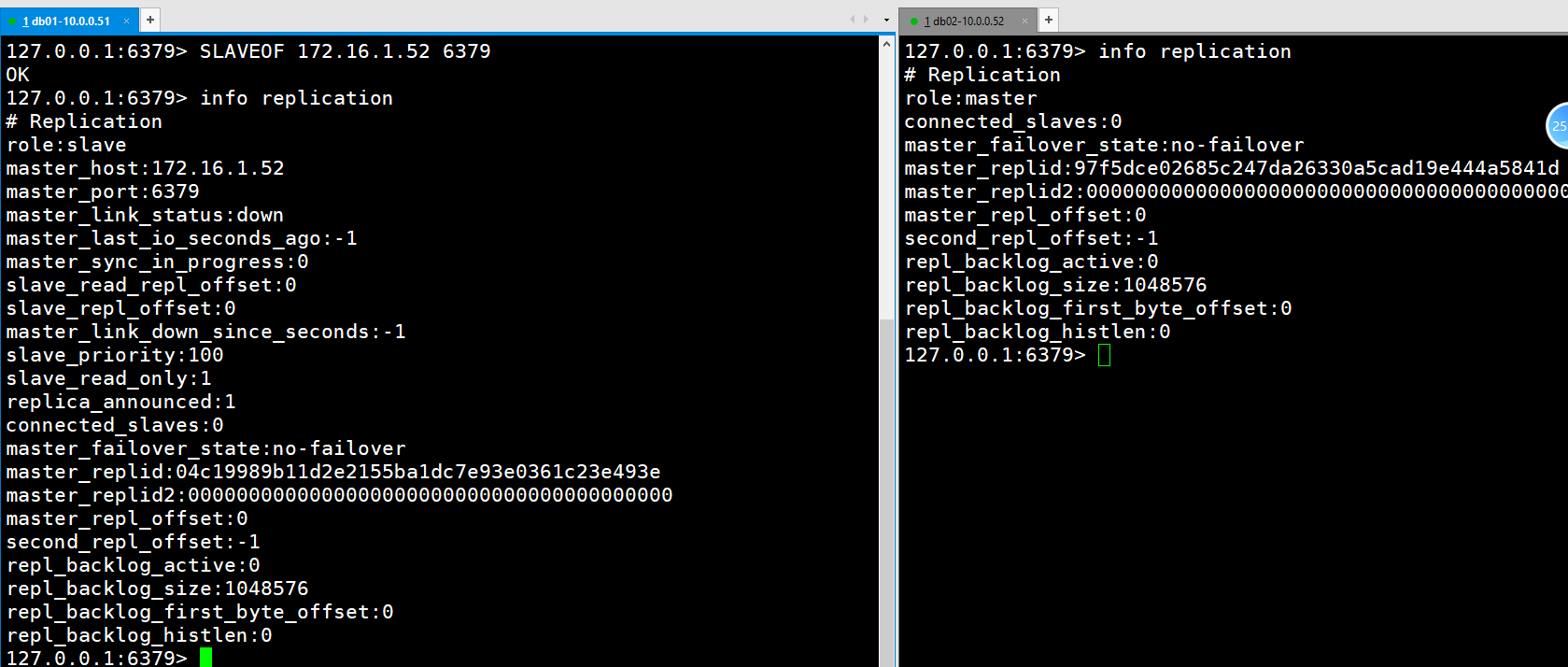
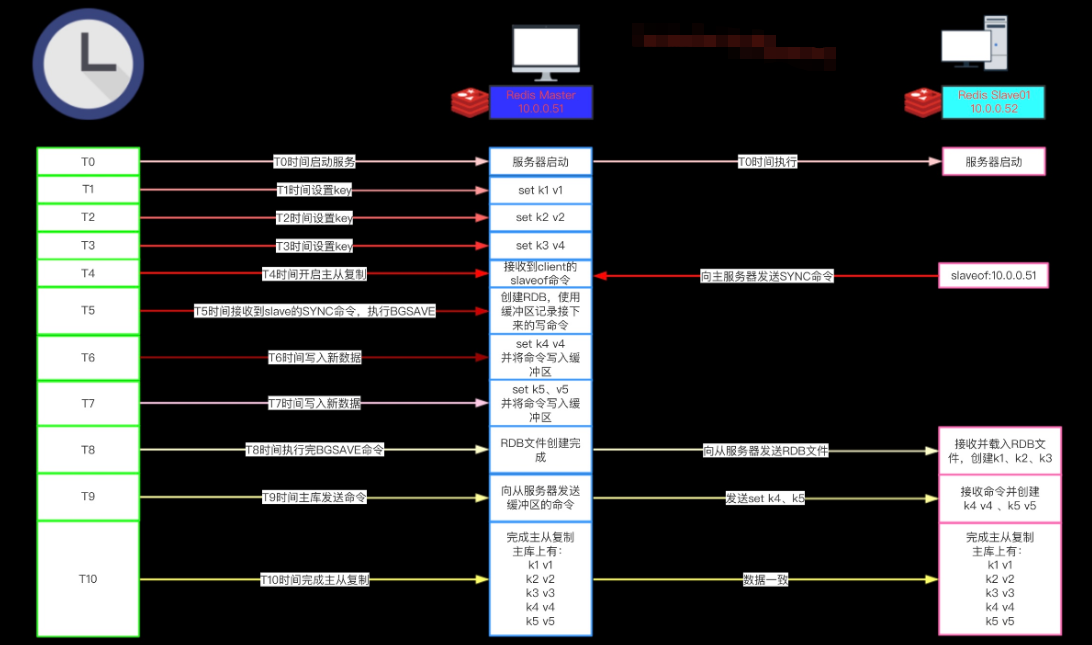
- 从服务器向主服务器发送 SYNC 命令。
- 接到 SYNC 命令的主服务器会调用BGSAVE 命令,创建一个 RDB 文件,并使用缓冲区记录接下来执
行的所有写命令。 - 当主服务器执行完 BGSAVE 命令时,它会向从服务器发送 RDB 文件,而从服务器则会接收并载入这
个文件。 - 主服务器将缓冲区储存的所有写命令发送给从服务器执行。

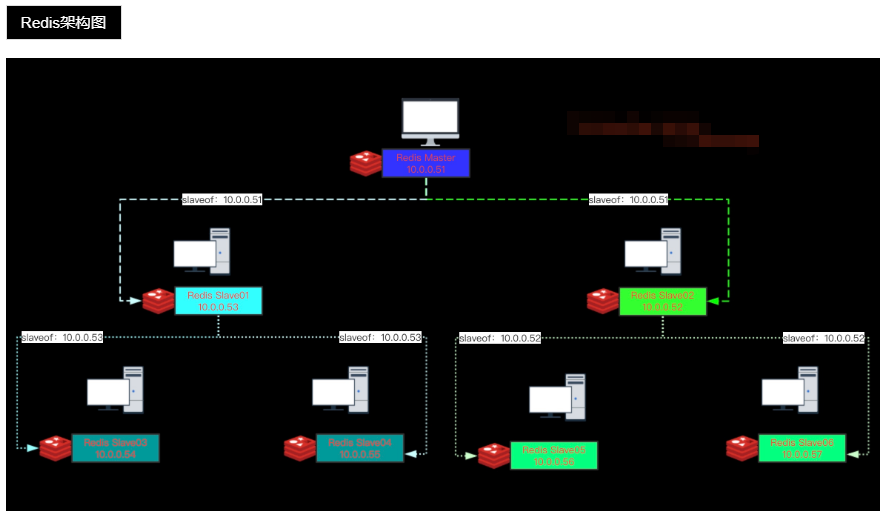
redis的主从复制部署
| 主机名 | 外网IP | 内网IP | 角色 | 应用 |
|---|---|---|---|---|
| db01 | 10.0.0.51 | 172.16.1.51 | 主库 | redis |
| db02 | 10.0.0.52 | 172.16.1.52 | 从库 | redis |
前提
- 开启rdb持久化 现版本自动开启、
- 安全模式要关闭
- bind监听
bind 10.0.0.51 172.16.1.51 127.0.0.1
操作步骤
1 | # 连接主库 db01 |
级联复制
前提
- 开启rdb持久化 现版本自动开启、
- 安全模式要关闭
- bind监听
bind 10.0.0.53 172.16.1.53 127.0.0.1
即从库下还有个从库
1 | # 配置从库身份(db02做主库) db03 |
多实例做主从步骤
1 | # 连接redis |
SYNC和PSYNC
sync命令实例
命令传播
在主从服务器完成同步之后,主服务器每执行一个写命令,它都会将被执行的写命令发送给从服务器执
行,这个操作被称为“命令传播”(command propagate)
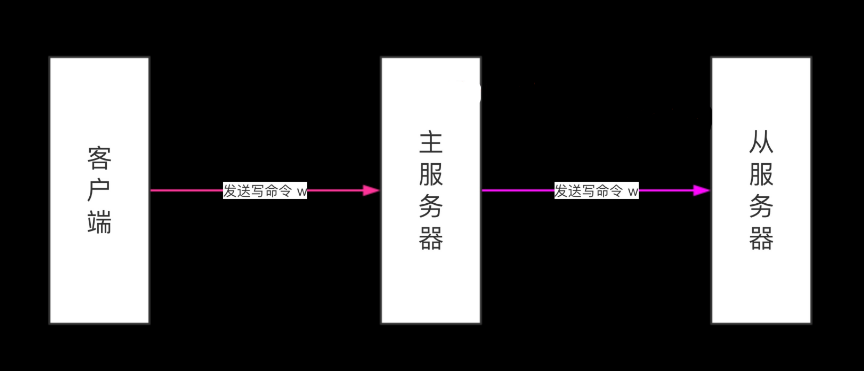
命令传播是一个持续的过程:只要复制仍在继续,命令传播就会一直进行,使得主从服务器的状态可以
一直保持一致
断线重连
突发场景
- 网络波动
- 服务器断电
- …..
SYNC
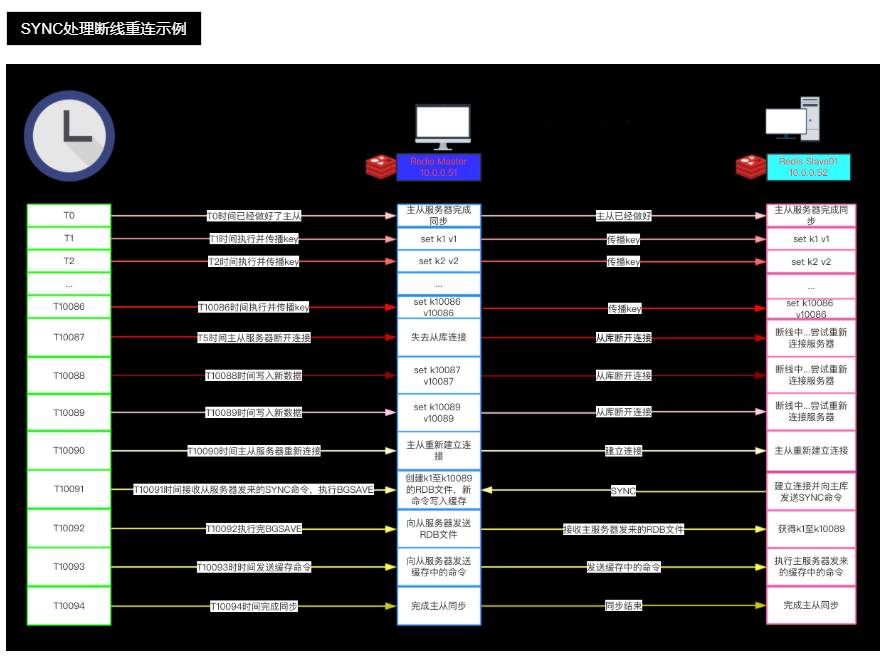
如果我们仔细地观察整个断线并重连的过程,就会发现:
从服务器在断线之前已经拥有主服务器的绝大部分数据,要让主从服务器重新回到一致状态,从服务器
真正需要的是 k10087、k10088和k10089这三个键的数据,而不是主服务器整个数据库的数据。SYNC
命令在处理断线并重连时的做法——将主服务器的整个数据库重新同步给从服务器,是极度浪费的!
PSYNC
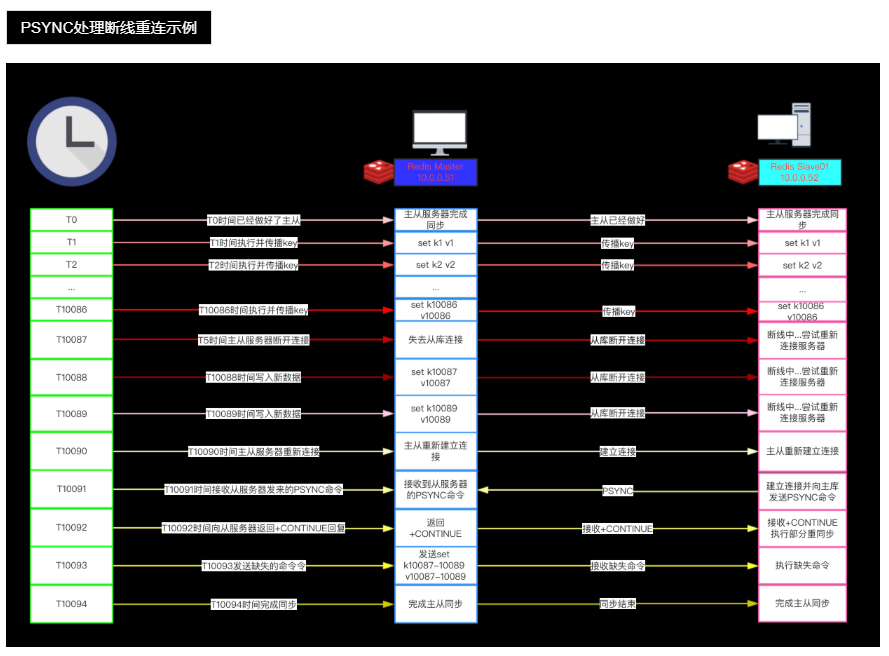
- PSYNC只会将从服务器断线期间缺失的数据发送给从服务器。两个例子的情况是相同的,但SYNC 需
要发送包含整个数据库的 RDB 文件,而PSYNC 只需要发送三个命令。 - 如果主从服务器所处的网络环境并不那么好的话(经常断线),那么请尽量使用 Redis 2.8 或以上版
本:通过使用 PSYNC 而不是 SYNC 来处理断线重连接,可以避免因为重复创建和传输 RDB文件而浪费
大量的网络资源、计算资源和内存资源。- 在读写分离环境下,客户端向主服务器发送写命令 SET k10086 v10086,主服务器在执行这个写命
令之后,向客户端返回回复,并将这个写命令传播给从服务器。 - 接到回复的客户端继续向从服务器发送读命令 GET k10086 ,并且因为网络状态的原因,客户端的
GET命令比主服务器传播的 SET 命令更快到达了从服务器。 - 因为从服务器键k10086的值还未被更新,所以客户端在从服务器读取到的将是一个错误(过期)的
k10086值。
- 在读写分离环境下,客户端向主服务器发送写命令 SET k10086 v10086,主服务器在执行这个写命
Redis是怎么保证数据安全的呢?
- 主服务器只在有至少N个从服务器的情况下,才执行写操作
- 从Redis 2.8开始,为了保证数据的安全性,可以通过配置,让主服务器只在有至少N个当前已连接从
服务器的情况下,才执行写命令。 - 不过,因为 Redis 使用异步复制,所以主服务器发送的写数据并不一定会被从服务器接收到,因此,
数据丢失的可能性仍然是存在的。 - 通过以下两个参数保证数据的安全:
1 | #执行写操作所需的至少从服务器数量 |
这个特性的运作原理:
- 从服务器以每秒一次的频率 PING 主服务器一次, 并报告复制流的处理情况。主服务器会记录各个
从服务器最后一次向它发送 PING 的时间。用户可以通过配置, 指定网络延迟的最大值 min-slavesmax-
lag , 以及执行写操作所需的至少从服务器数量 min-slaves-to-write 。 - 如果至少有 min-slaves-to-write 个从服务器, 并且这些服务器的延迟值都少于 min-slaves-max-lag
秒, 那么主服务器就会执行客户端请求的写操作。你可以将这个特性看作 CAP 理论中的 C 的条件放宽
版本: 尽管不能保证写操作的持久性, 但起码丢失数据的窗口会被严格限制在指定的秒数中。 - 另一方面, 如果条件达不到 min-slaves-to-write 和 min-slaves-max-lag 所指定的条件, 那么写操
作就不会被执行, 主服务器会向请求执行写操作的客户端返回一个错误。
如果主库挂了
1 | # 宕掉主机 |
 wechat
wechat alipay
alipay



{kind=link}